Инциденты, которые Служба Service Desk сразу не может разрешить, могут быть переданы для обработки одной из специализированных групп. Разрешение или Обходное решение должно быть представлено в максимально короткие сроки для того, чтобы восстановить обслуживание Пользователей с минимальным влиянием на их работу. После устранения причины Инцидента и восстановления согласованной услуги Инцидент закрывается.
На Рисунке 5.2 показаны процессы, происходящие в течение жизненного цикла Инцидента. В Приложении 5Д эти процессы представлены с другой точки зрения.
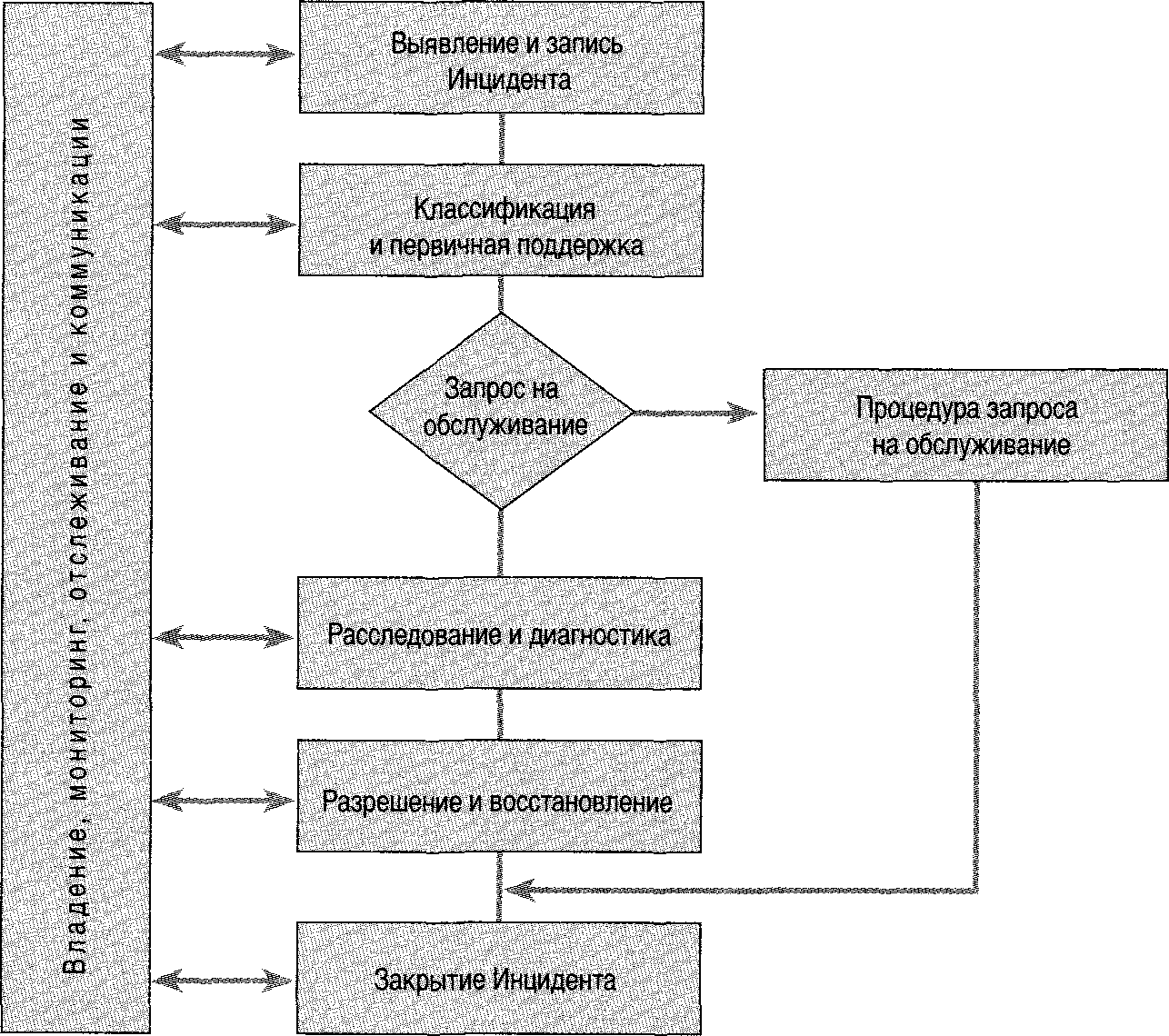
Рисунок 5.2 - Жизненный цикл Инцидента.
Статус Инцидента отражает его текущее положение в жизненном цикле, иногда называемое «позицией в диаграмме последовательности выполняемых действий». Каждый сотрудник должен знать все возможные статусы и их значения. Несколько примеров категорий статусов:.
■ новый;.
■ принят;.
■ определены сроки;.
■ назначен/передан специалисту;.
■ в работе (Work In Progress, WIP);.
■ ожидание;.
■ разрешен;.
■ закрыт.
В течение жизненного цикла Инцидента важно, чтобы запись о нем поддерживалась в актуальном состоянии. Это позволит любому сотруднику группы обслуживания предоставлять Заказчику самые свежие данные о ходе обработки запроса. Некоторые примеры действий по обновлению записей:.
■ обновить исторические сведения;.
■ изменить статус (например, со статуса «новый» на статус «в работе» или «ожидание»);.
■ изменить влияние на бизнес и приоритет;.
■ ввести потраченное время и затраты;.
■ отследить статус эскалации.
Описание, первоначально заявленное Заказчиком, может измениться по ходу жизненного цикла Инцидента. Тем не менее, важно оставить описание исходных симптомов как для анализа, так и для того, чтобы можно было ссылаться на жалобу, используя формулировки, содержащиеся в первоначальном запросе. Например, Заказчик мог заявить, что не работает принтер, а было определено, что неполадка была вызвана сбоем в сети. При ответе Заказчику сначала лучше объяснить, что Инцидент с принтером разрешен, вместо того чтобы говорить о разрешении проблем с сетью.
Проверенная история Инцидента необходима при анализе хода его обработки, особенно это важно при разрешении вопросов, связанных с нарушением SLA. В ходе жизненного цикла Инцидента следует регистрировать следующие обновления записи о нем:.
■ имя человека, сделавшего изменение в записи;.
■ дата и время изменения;.
■ что именно этот человек изменил (например, приоритет, статус, историю);.
■ почему было внесено изменение;.
■ потраченное время.
Если внешним поставщикам запрещено обновлять записи Службы Service Desk (что и рекомендуется), тогда необходимо определить процедуру обновления записей за поставщика. Это гарантирует надлежащий учет использованных ресурсов. Тем не менее, если программное обеспечение допускает возможность выделить класс Инцидентов, устраняемых внешними поставщиками, и проводить предварительную проверку введенной информации, то в некоторых организациях может оказаться весьма удобным разрешить внешним поставщикам обновлять информацию напрямую. В случае принятия такого решения вам необходимо определить, какую информацию вы не готовы предоставить поставщику и насколько подробно вы должны быть информированы о действиях поставщика.
Такая же ситуация может возникнуть, когда Служба Service Desk обновляет запрос вместо специалиста службы технической поддержки, находящегося вне офиса. Иногда может понадобиться обновить учетную запись Инцидента постфактум, например, если специалисты работают в вечернее время, а Служба Service Desk должна обновлять записи вместо них на следующее утро.
5.3.2 Первая, вторая и третья линии поддержки.
Часто подразделения и (специализированные) группы поддержки, не входящие в состав Службы Service Desk, называются группами поддержки второй или третьей линии. Они обладают более специализированными навыками, дополнительным временем или другими ресурсами для разрешения Инцидентов. Исходя из этого, Служба Service Desk называется первой линией поддержки. На Рисунке 5.3 показано, как эта терминология связана с действиями в процессе Управления инцидентами, о которых говорилось в предыдущих параграфах.
Заметьте, что третья и/или N-я линия поддержки могут со временем включать внешних поставщиков, которые могут иметь прямой доступ к средствам регистрации Инцидентов (в зависимости от правил безопасности и технических вопросов).
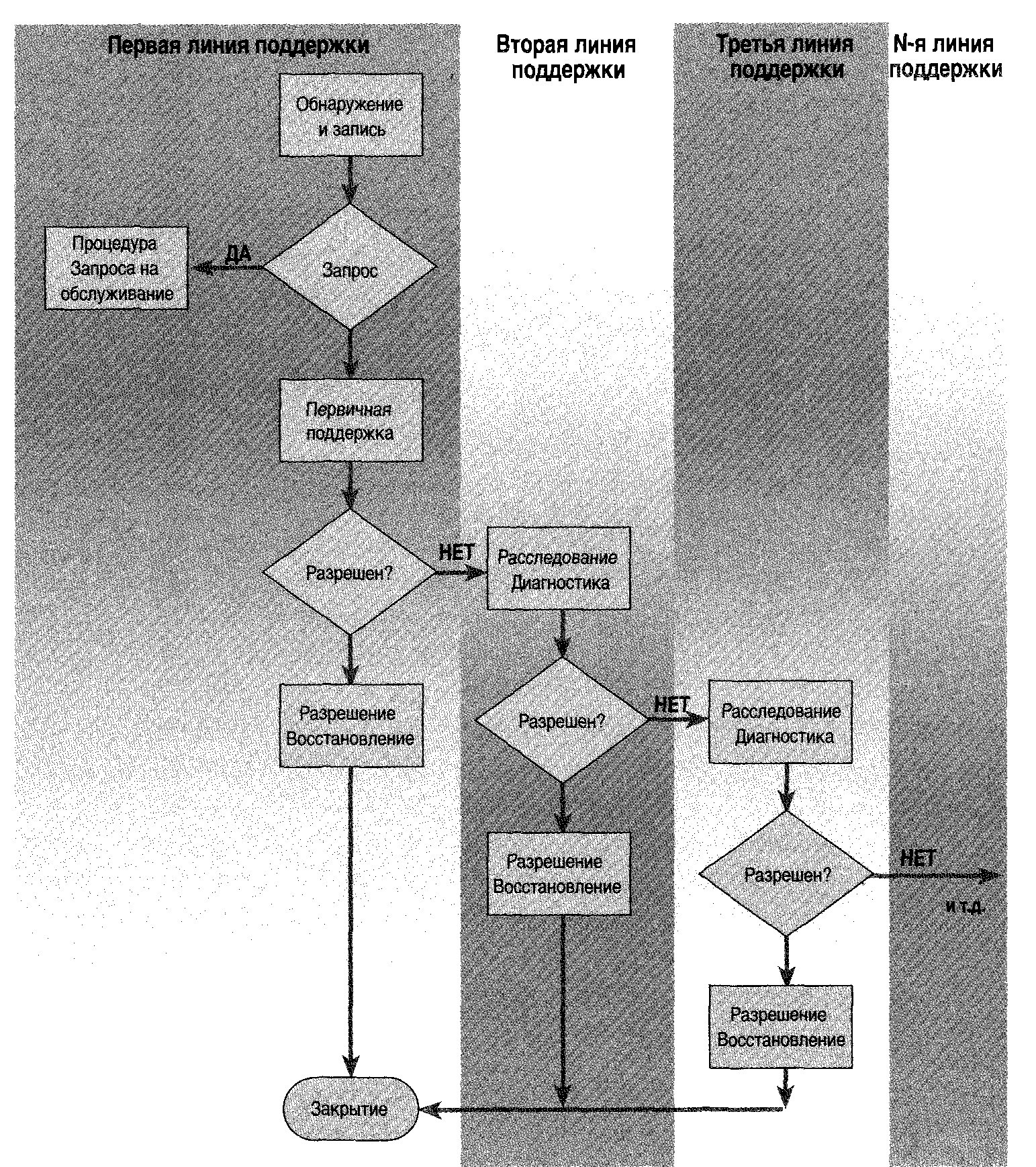
Рисунок 5.3 ~ Первая, вторая и третья линии поддержки.
5.3.3 Сравнение функциональной и иерархической эскалации.
«Эскалация» - механизм, способствующий своевременному разрешению Инцидента. Он может сработать на любом этапе процесса разрешения.
Передача Инцидента от групп поддержки первой линии к группам поддержки второй линии или дальше называется «функциональной эскалацией» и происходит по причине недостатка знаний или квалификации. Предпочтительно, чтобы функциональная эскалация происходила в случаях, когда истекает согласованное время, отведенное на разрешение Инцидента. Автоматическая функциональная эскалация, которая вызывается по истечении определенного периода времени, должна быть тщательно спланирована и не должна превышать согласованное (в SLA) время разрешения.
«Иерархическая эскалация» может произойти в любой момент процесса разрешения, если существует вероятность того, что разрешение Инцидента не удастся завершить вовремя или оно окажется неудовлетворительным. В случае, если не хватает знаний или квалификации, иерархическая эскалация обычно производится вручную (Службой Service Desk или другим персоналом поддержки). Возможность проведения автоматической иерархической эскалации может рассматриваться после некоторого критичного периода времени, когда становится очевидным, что своевременно разрешить Инцидент не удастся. Предпочтительно, чтобы эскалация происходила задолго до истечения времени, отведенного (в SLA) на разрешение. Это позволит линейному руководству, имеющему соответствующие полномочия, принять меры по исправлению ситуации, например нанять специалистов внешнего поставщика.
5.3.4 Приоритет.
Приоритет Инцидента первоначально определяется его влиянием на бизнес и срочностью, с которой необходимо обеспечить разрешение или Обходное решение. Целевые показатели для разрешения Инцидентов или обработки запросов обычно включаются в SLA. На практике целевые показатели разрешения Инцидентов часто связаны с категориями. Примеры категорий и приоритетов, а также систем их кодирования, можно найти в Приложениях 5А и 5Б соответственно.
Службе Service Desk отводится важная роль в процессе Управления инцидентами:.
■ обо всех Инцидентах сообщается в Службу Service Desk, и ее сотрудники регистрируют Инциденты; в случаях, когда Инциденты генерируются автоматически, процесс все равно должен включать регистрацию через Службу Service Desk;.
■ основная масса Инцидентов (возможно, до 85% при высоком уровне навыков персонала) будет разрешена Службой Service Desk;.
■ Служба Service Desk - «независимое» подразделение, которое наблюдает за ходом разрешения всех зарегистрированных Инцидентов.
Ниже приведен перечень основных действий, которые выполняются Службой Service Desk после получения уведомления об Инциденте:.
■ запись основных сведений - включая время и полученные подробности о симптомах;.
■ если сделан запрос на обслуживание, заявка обрабатывается в соответствии со стандартными процедурами в данной организации;.
■ для дополнения записи об Инциденте на основе CMDB происходит выбор Учетных элементов (УЭ), являющихся, по сообщению, причиной Инцидента;.
■ установка соответствующего приоритета и передача Пользователю уникального номера Инцидента, автоматически генерируемого системой (чтобы сообщать его при дальнейших обращениях в службу);.
■ оценка Инцидента и, по возможности, предоставление рекомендаций по его разрешению: часто это возможно для стандартных Инцидентов или, когда его причиной является известная Проблема/ошибка;.
■ закрытие записи об Инциденте после его успешного разрешения: добавление сведений о действиях, связанных с разрешением, и установка соответствующего кода категории;.
■ передача Инцидента группе поддержки второй линии (т.е. специализированной группе) после неудачной попытки разрешения или при выяснении того, что необходим более высокий уровень поддержки.
5.3.5 Связи между Инцидентами, Проблемами, Известными ошибками и Запросами на Изменение (RFC).
Инциденты, возникшие в результате отказов или ошибок в ИТ-инфраструктуре, приводят к реальным или потенциальным отклонениям от запланированной работы ИТ-услуг.
Причина Инцидентов может быть очевидна, и тогда для устранения этой причины не потребуется дальнейшее расследование. В результате будет проведен ремонт, определено Обходное решение или оформлен RFC, который исправит ошибку. В некоторых случаях устранить сам Инцидент - т.е. его влияние на Заказчика можно довольно быстро. Возможно, просто требуется перезагрузка компьютера или повторная инициализация канала связи без выявления причины, лежащей в основе Инцидента.
В случаях, когда исходная причина Инцидента неизвестна, возможно, следует оформить запись о Проблеме. Таким образом, Проблема на самом деле является показателем неизвестной ошибки в инфраструктуре. Обычно запись о Проблеме оформляется только тогда, когда необходимость ее расследования оправдана серьезностью проблемы.
Влияние такой Проблемы часто будет оцениваться на основе влияния (как реального, так и потенциального) на бизнес-услуги, а также на основе числа заявленных похожих Инцидентов, которые, возможно, имеют одну и ту же исходную причину. Создание учетной записи Проблемы может быть уместно даже тогда, когда последствия Инцидента были устранены. Следовательно, запись о Проблеме может рассматриваться независимо от связанных с ней записей об Инцидентах, и как запись о Проблеме, так и расследование ее причины может продолжаться даже после того, как первоначальный Инцидент был успешно закрыт.
Успешная обработка записи о Проблеме приведет к идентификации корневой ошибки; эта запись может стать записью Известной ошибки после того, как разработано Обходное решение и/или RFC. Эта логическая цепочка, от первоначального уведомления до разрешения исходной проблемы, показана на Рисунке 5.4.

Рисунок 5.4 - Связи между Инцидентами, Проблемами, Известными ошибками и Запросами на Изменение (RFC).
Таким образом, мы имеем следующие определения:.
■ Проблема: неизвестная исходная причина одного и более Инцидентов.
■ Известная ошибка: Проблема, которая успешно диагностирована и для которой известно Обходное решение.
■ RFC: Запрос на Изменение любого компонента ИТ-инфраструктуры или любого аспекта ИТ-услуг.
Проблема может привести к множеству Инцидентов; также возможно, что Проблема не будет диагностирована до тех пор, пока не случится несколько Инцидентов в какой-нибудь период времени. Обработка Проблем значительно отличается от обработки Инцидентов и, следовательно, описана процессом Управления проблемами.
Во время процесса разрешения Инцидент проверяется на наличие связей в базе данных Проблем и Известных ошибок. Его также следует проверить на наличие связей в базе данных Инцидентов, чтобы определить, существуют ли похожие незакрытые Инциденты, и были ли разрешены предыдущие похожие Инциденты. Если уже доступно Обходное решение или разрешение, Инцидент может быть сразу же разрешен. В противном случае, процесс Управления инцидентами несет ответственность за разрешение или поиск Обходного решения с минимальным прерыванием бизнес-процесса.
Когда процесс Управления инцидентами находит Обходное решение, оно будет проанализировано командой Управления проблемами, которая потом обновит соответствующую запись о Проблеме (см. Рисунок 5.5). Необходимо отметить, что соответствующая запись о Проблеме может в этот момент еще не существовать например, Обходное решение может состоять в том, чтобы отослать отчет по факсу из-за сбоя в канале связи, но записи о Проблеме по поводу этого сбоя в канале связи может еще не быть; в этом случае команда Управления проблемами должна ее создать. Итак, в процесс входят действия, когда Служба Service Desk связывает Инциденты, которые являются результатом зарегистрированной Проблемы.
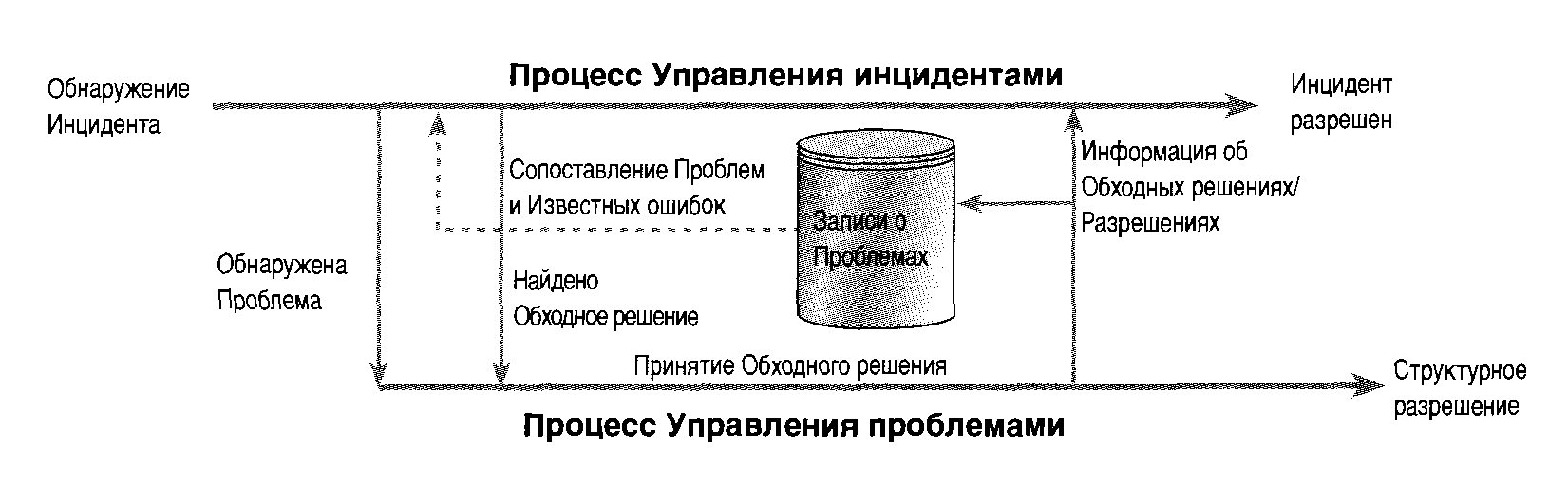
Рисунок 5.5 - Обработка Обходных решений и разрешений инцидента.
Также возможно, что группа Управления проблемами во время расследования Проблемы, связанной с Инцидентом, найдет Обходное решение или разрешение самой Проблемы и/или некоторых связанных с ней Инцидентов. В этом случае группа Управления проблемами должна сообщить об этом процессу Управления инцидентами для того, чтобы изменить статус открытых Инцидентов на «Известная ошибка» или «Закрыт».
Когда во время регистрации Инцидента предполагается, что этот Инцидент должен рассматриваться как Проблема, тогда он должен быть сразу же направлен на рассмотрение в процесс Управления проблемами, где, при необходимости, оформляется новая запись о Проблеме. Процесс Управления инцидентами будет, как всегда, нести ответственность за продолжение работы по разрешению Инцидента для минимизации его влияния на бизнес-процессы.