Инцидентов в будущем. (Реагирующий) Процесс контроля Проблем состоит из трех этапов:.
■ идентификация и запись Проблемы;.
■ классификация проблемы - с точки зрения влияния на бизнес;.
■ расследование и диагностика Проблемы.
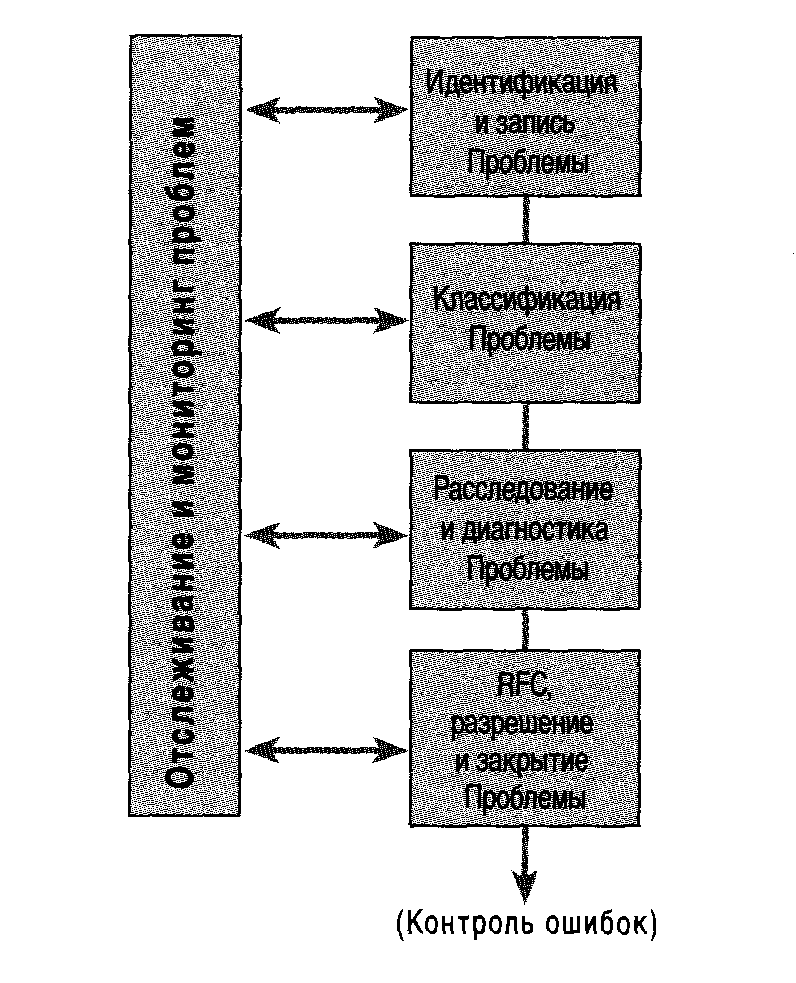
Рисунок 6.1 - Контроль Проблем.
Когда корневая причина определена, начинается процесс контроля ошибок.
6.6.1 Идентификация и запись Проблемы.
Идентификация Проблемы происходит, когда:.
■ на этапе первичной поддержки и классификации Инцидента не удалось привязать его к существующим Проблемам и Известным ошибкам;.
■ анализ данных Инцидента показывает, что идет речь о повторяющихся Инцидентах;.
■ анализ данных Инцидента показывает Инциденты, которые еще не связаны с существующими Проблемами или Известными ошибками;.
■ анализ ИТ-инфраструктуры указывает на Проблему, которая потенциально может привести к Инцидентам;.
■ возникает крупный или значительный Инцидент (который обладает серьезным отрицательным влиянием на услуги, предоставляемые Заказчику), для которого необходимо найти структурное решение.
Необходимо заметить, что некоторые Проблемы могут быть определены персоналом, не состоящим в команде Управления проблемами, например Управлением мощностями. Независимо от этого все Проблемы должны быть записаны и стать известными в рамках процесса Управления проблемами. Значительная часть процесса Управления доступностью связана с обнаружением и предупреждением Проблем и Инцидентов ИТ-инфраструктуры, следовательно, взаимодействие между этими двумя областями важно для улучшения качества обслуживания.
Совет:.
Управление проблемами требует усилий и ресурсов, следовательно, приводит к значительным затратам. Организация может решить, что усилия и затраты не оправданы для некоторых типов Инцидентов, не соотнесенных с Проблемами и Изученными ошибками - возможно это Инциденты, для которых есть возможность быстрого разрешения и которые обладают низкой степенью влияния или низкой вероятностью повторения. В этих случаях в CMDB создается пустая запись о Проблеме, относящаяся ко всем связанным с ней Инцидентам, Известным ошибкам, RFC и УЭ.
Записи о Проблемах должны быть записаны в базу данных (в идеале, в CMDB). Эти записи очень похожи на записи об Инцидентах. Они обычно не включают некоторые стандартные для Инцидентов данные (например, данные о Пользователе), которые неуместны. Тем не менее, записи о Проблемах соединены со всеми сопутствующими им записями об Инцидентах. Решение или Обходные решения Инцидентов должны быть записаны в соответствующих записях о Проблемах для обеспечения доступа остальному персоналу на случай, если возникнут повторные Инциденты.

Рисунок 6.2 - Ход процесса привязки Инцидента.
Процесс идентификации Проблем, показанный на Рисунке 6.2. включает основную классификацию Проблем. Данные о затронутых Учетных элементах должны быть добавлены к основным классификационным данным. В идеале эти Учетные элементы должны быть самого нижнего учитываемого уровня, например, модуль кода приложения или компонент аппаратного обеспечения. Идентификация проблемного УЭ на этом уровне зачастую невозможна на этапе идентификации Проблемы.
6.6.2 Классификация Проблемы.
После определения Проблемы, необходимо установить объем усилий, требуемых для нахождения и восстановления вышедшего(их) из строя УЭ. Поэтому важно иметь представление о влиянии Проблемы на существующие уровни обслуживания. Этот процесс известен как «классификация». На практике, усилия по поддержке направляются только на небольшое количество Проблем, которые связаны только с одним Инцидентом.
Шаги для классификации Проблем похожи на шаги для классификации Инцидентов; они должны определить:.
■ категорию;.
■ влияние;.
■ срочность;.
■ приоритет.
Присваивание категорий Проблемам осуществляется по связанным группам или областям знаний (например, аппаратное обеспечение, программное обеспечение, ПО поддержки и т.п.). Эти группы могут совпадать с областями организационной ответственности или сегментам Пользователей и Заказчиков и являются базисом для распределения Проблем персоналу службы поддержки. Приложение 6А дает пример простой и эффективной структуры категорий Проблем.
После идентификации новой Проблемы необходимо провести объективный анализ ее влияния (т.е. ее влияния на бизнес). Взаимоотношения между компонентами в ИТ-инфраструктуре, зарегистрированные в CMDB, могут оказать значительную помощь при определении степени влияния Проблемы.
Организации должны спроектировать свою собственную систему кодов влияния, связанную с нуждами их бизнеса. Коды влияния - очень полезный механизм для эффективного распределения усилий по поддержке. Последующее включение простых уровней приоритетов, зависимых от влияния, обеспечит механизм полного контроля.
При определении влияния Проблемы значительную помощь могут оказать связи между компонентами в ИТ-инфраструктуре, зарегистрированные в CMDB. В CMDB можно найти Учетные элементы, которые зависят от части Учетного элемента в ИТ-инфраструктуре, с которым связан Инцидент, или которые идентичны этому Учетному элементу.
Срочность - это степень задержки, которую можно допустить при разрешении Проблемы или ошибки; ее необходимо отличать от приоритета. Приоритет показывает относительную последовательность, в которой следует обрабатывать Инциденты, Проблемы, Изменения или ошибки. При определении приоритета принимаются во внимание риски и доступность ресурсов, но в основном его определение базируется на комбинации срочности и влияния. Несмотря на низкую степень влияния на бизнес, некоторые задачи, требующие срочного разрешения, будут обработаны раньше задач с очень высоким влиянием на бизнес, но с более низкой срочностью. Иногда полезно присвоить некоторые числовые значения каждой задаче, для того чтобы из них вывести числовой приоритет; но, также как и в других областях Управления услугами, эти числа должны быть модифицированы на основе здравого смысла и осведомленности о бизнесе. Тем не менее, полезная и простая отправная точка - указать числовые значения от 1 до 4 для каждой степени срочности и влияния и потом суммировать их для всех Проблем, что укажет относительный приоритет. После этого организация должна наблюдать и критически оценивать результирующие приоритеты и следить, чтобы ее деятельность отражала их требования. Как «срочность», так и «приоритет» показаны в Приложении А (Глоссарий терминов). Примеры аспектов, влияющих на срочность:.
■ доступность временного устранения ошибки;.
■ существование Обходного решения;.
■ возможность планируемой задержки разрешения;.
■ осведомленность о будущем влиянии на бизнес, например оборудование, требуемое для поддержки процессов, выполняемых в конце месяца.
Для каждого Инцидента, Проблемы и Изменения будут указаны как влияние на бизнес-услуги, так и срочность:.
■ влияние указывает степень уязвимости бизнеса;.
■ срочность демонстрирует время, доступное для предотвращения, или по крайней мере уменьшения этого влияния.
Советы:.
■ Укажите код влияния для всех Проблем при первой возможности. Когда это сделано, важно обеспечить доступ ко всем Проблемам для процесса управления назначением персонала перед тем, как начнется подробное расследование. Назначенный исполнитель принимает ответственность за Проблему и становится ключевым звеном всех коммуникаций для координации действий по разрешению этой Проблемы. Составьте график на основании степени влияния, чтобы крупные Проблемы рассматривались сразу же. Убедитесь, ч то процесс контроля ресурсов позволяет обрабатывать Проблемы с низкой степенью влияния, которые превысили предел времени, отведенного для их разрешения.
■ Процесс анализа влияния имеет одно значительное ограничение: он показывает только ситуацию и какой-либо момент времени.
Даже если Проблеме был корректно назначен код влияния низкой степени, большое количество последующих Инцидентов, привязанных к Hcii позже, может потребонать немедленного внимания к этой Проблеме. Необходимо указывать пороговые значения по устранению Инциденте и, учитывая эту сложность.
Как показано на Рисунке 6.2. процесс Управления проблемами может быть спроектирован так, чтобы подсчитывать Инциденты, для которых найдены связи с учетными записями Проблем (или Известных ошибок). Системы контроля Проблем и ошибок периодически проверяют этот счетчик, сравнивая его.
с определенным пороговым значением. Когда счетчик становится равным или превышает допустимое пороговое значение, для таких Проблем/Известных ошибок необходимо провести эскалацию, чтобы им уделили немедленное внимание.
Тем не менее, помните, что количество не всегда тождественно важности: Проблема, которая предотвращает ввод (),.j% заказов, может внезапно и корректно быть распознана как критическая, когда окажется, что невозможно ввести сумму заказа, превышающую £999 999.99!.
Процесс расследования Проблемы похож на процесс расследования Инцидента (см. главу 5). но основные цели этих процессов значительно отличаются. Цель Управления инцидентами - быстрое восстановление услуг, тогда как цель Управления проблемами - диагностика корневой причины. Действия по расследованию должны включать доступные Обходные решения Инцидентов, связанных с Проблемой, на основе информации в базе данных записей об Инцидентах. Действия Управления проблемами должны включать обновление рекомендованных Обходных решений в записи о Проблеме для поддержки контроля Инцидентов.
Диагностика часто показывает, что причина Проблемы заключена в процедуре, и не является ошибкой в зарегистрированном Учетном элементе (элемент аппаратного или программного обеспечения, документации или процедуры).. Пример - неправильный релиз версии программы. Эти ситуации приводят к закрытию Проблемы с соответствующим кодом категории. Проблемы этого класса не всегда автоматически достигают формального статуса Известной ошибки. Чтобы довести работу над этими Проблемами до конца и принять меры по их решению, рассмотрите возможность создания пустой записи об Учетном элементе для процедуры, вызывающей Проблему, и повторной классификации Проблемы как Известной ошибки или оформления RFC.
В результате диагностики была найдена причина неисправности в зарегистрированном Учетном элементе. Теперь статус Проблемы автоматически заменяется на статус Известной ошибки. В этот момент начинает работать система контроля ошибок и соответствующие процедуры.
Как было указано ранее, цели расследования Проблемы часто конфликтуют с целями разрешения Инцидента. Например, расследование Проблемы может потребовать данные по подробной диагностике, которые доступны только тогда, когда возникает Инцидент; сбор этих данных может значительно задержать восстановление нормального обслуживания. Убедитесь в том, что поддерживается тесная связь с процессом контроля Инцидентов и эксплуатационной службой или службами управления сетью, чтобы обеспечить сбалансированный взгляд на то, когда лучше проводить подобные действия.
Методы анализа Проблем.
Литература предоставляет различные методы по структурному анализу и диагностике Проблем. Вот некоторые доступные методы:.
■ Кепнер и Трего (Kepner and Tregoe - см. Приложение 6Б);.
■ Диаграммы Ишикавы (Ishikawa - см. Приложение 6В);.
■ метод «мозгового штурма»;.
■ методы блок-схем.
Управление проблемами должно выбрать методы, которые наилучшим образом соответствуют целям организации.
Следует помнить следующие моменты по отношению к контролю Проблем:.
■ Определение категории Инцидентов может обеспечить первый шаг в направлении определения Проблемы. Следовательно, Управление проблемами должно быть тесно связано с Управлением инцидентами при разработке общих категорий Инцидентов и Проблем. Соответствующие категории должны быть созданы как для регистрации Инцидентов, которые должны быть описаны в «терминах Заказчика», так и для записи установленных причин, выраженных в «терминах ИТ».
■ Если возможно, составьте команду из специалистов различных направлений, с координатором, назначенным, например, от процесса Управления проблемами. Это позволит охватить как можно больше различных аспектов в ходе расследования.
■ Удостоверьтесь, что вовлеченные специалисты службы поддержки обладают соответствующими средствами и диагностическим оборудованием для того, чтобы эффективно выполнять поставленные задачи.
■ Если Проблема вызвана не ошибкой в компоненте системы, а, например, общей нехваткой знаний Пользователей, выполните любые действия по разрешению, направленные на устранение этой Проблемы, и закройте запись о Проблеме. В качестве альтернативы можно создать новую запись об Учетном элементе - например, для «Проблем, связанных с обучением». В дальнейшем эта Проблема может быть переведена в статус Известной ошибки в обычном порядке. Удостоверьтесь, что найденная причина отражает реальную ситуацию например, недостаток знаний пользователей и тренингов.
■ В ходе процесса контроля Инцидентов или Проблем процедуры расследования требуют доступа к документации на все продукты в ИТинфраструктуре в качестве справочной информации как для процесса, так и для персонала службы поддержки. Эта информация должна включать документацию по:.
прикладным системам;.
системному программному обеспечению;.
внутренним сервисным программам;.
сетевому аппаратному и программному обеспечению;.
общим диаграммам конфигураций/сети.
■ В дополнение к информации о продуктах также необходимо обеспечить эффективные процедуры по сбору диагностических данных, связанных с разрешением Проблем. Особенно важно, чтобы персонал службы поддержки был знаком с этими процедурами, так как любое их неверное использование во время Инцидента может задержать восстановление нормального предоставления ИТ-услуг. Также вам будут необходимы процедуры, которые поддерживают и приводят в.
исполнение требования процесса - в число этих процедур может входить соответствующее обучение, квалификация, и т.д.
■ Часто специалисты службы поддержки вовлечены как в процесс Управления инцидентами, так и в процесс Управления проблемами. Помня о различных целях этих процессов (быстрое разрешение по сравнению со структурными разрешениями), может быть полезно назначить специалистов на два процесса сразу, распределив при этом их рабочее время, возможно, 80% на Управление инцидентами и 20% на Управление проблемами. Это предотвратит полную концентрацию специалистов на реагирующем Управлении инцидентами.
■ Во время расследования Инцидентов и Проблем персоналу Управления проблемами также требуются точные учетные записи о последних Изменениях, поскольку они могут указать на причины Инцидентов или Проблем.